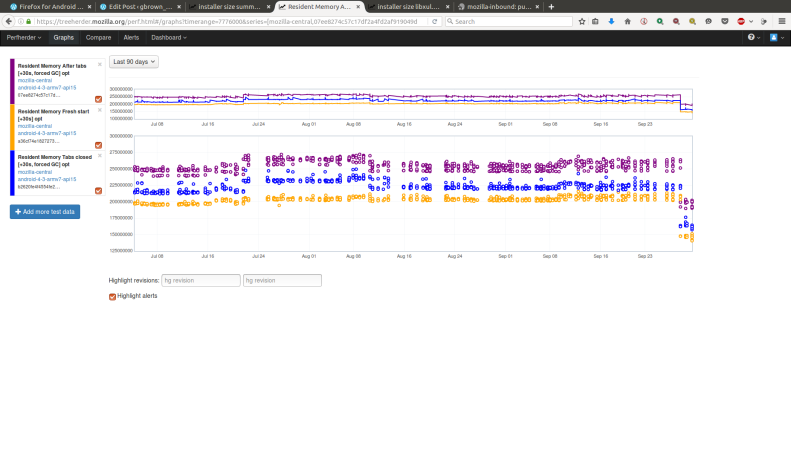
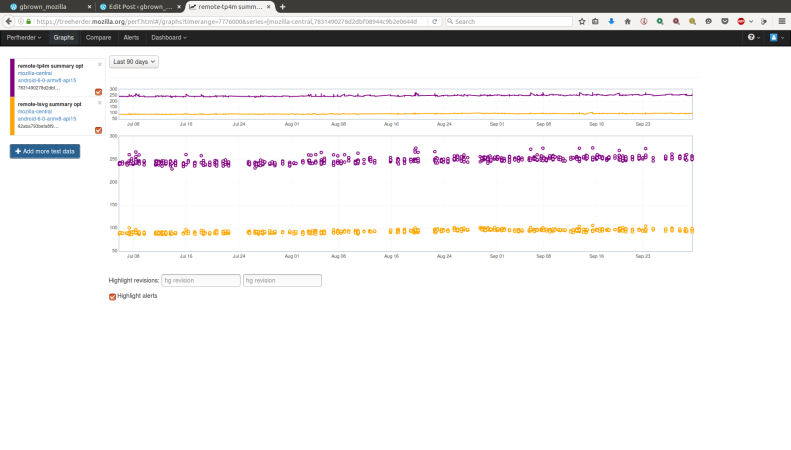
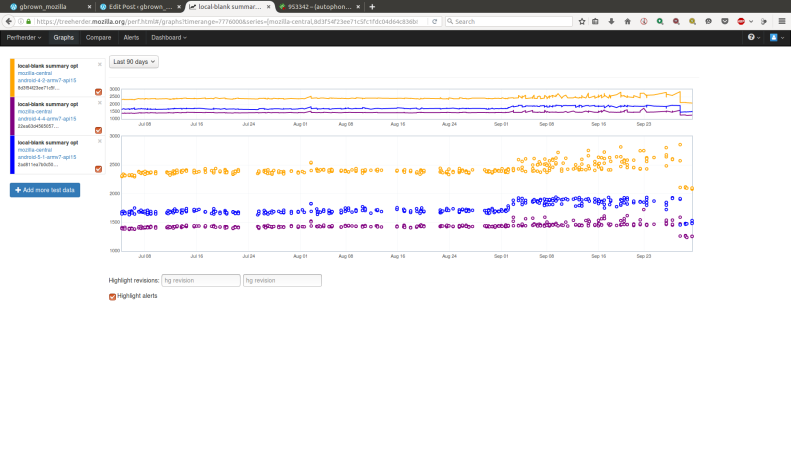
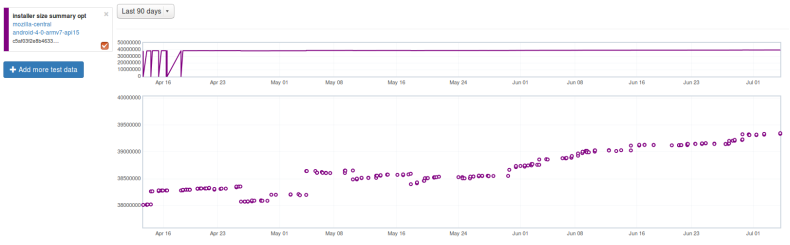
When a bug for an intermittent test failure needs attention, who should be contacted? Who is responsible for fixing that bug? For as long as I have been at Mozilla, I have heard people ask variations of this question, and I have never heard a clear answer.
There are at least two problematic approaches that are sometimes suggested:
- The test author: Many test authors are no longer active contributors. Even if they are still active at Mozilla, they may not have modified the test or worked on the associated project for years. Also, making test authors responsible for their tests in perpetuity may dissuade many contributors from writing tests at all!
- The last person to modify the test: Many failing tests have been modified recently, so the last person to modify the test may be well-informed about the test and may be in the best position to fix it. But recent changes may be trivial and tangential to the test. And if the test hasn’t been modified recently, this option may revert to the test author, or someone else who isn’t actively working in the area or is no longer familiar with the code.
There are at least two seemingly viable approaches:
- “You broke it, you fix it”: The person who authored the changeset that initiated the intermittent test failure must fix the intermittent test failure, or back out their change.
- The module owner for the module associated with the test is responsible for the test and must find someone to fix the intermittent test failure, or disable the test.
Let’s have a closer look at these options.
The “you broke it, you fix it” model is appealing because it is a continuation of a principle we accept whenever we check in code: If your change immediately breaks tests or is otherwise obviously faulty, you expect to have your change backed out unless you can provide an immediate fix. If your change causes an intermittent failure, why should it be treated differently? The sheriffs might not immediately associate the intermittent failure with your change, but with time, most frequent intermittent failures can be traced back to the associated changeset, by repeating the test on a range of changesets. Once this relationship between changeset and failure is determined, the changeset needs to be fixed or backed out.
A problem with “you broke it, you fix it” is that it is sometimes difficult and/or time-consuming to find the changeset that started the intermittent. The less frequent the intermittent, the more tests need to be backfilled and repeated before a statistically significant number of test passes can be accepted as evidence that the test is passing reliably. That takes time, test resources, etc.
Sometimes, even when that changeset is identified, it’s hard to see a connection between the change and the failing test. Was the test always faulty, but just happened to pass until a patch modified the timing or memory layout or something like that? That’s a possibility that always comes to mind when the connection between changeset and failing test is less than obvious.
Finally, if the changeset author is not invested in the test, or not familiar with the importance of the test, they may be more inclined to simply skip the test or mark it as failing.
The “module owner” approach is appealing because it reinforces the Mozilla module owner system: Tests are just code, and the code belongs to a module with a responsible owner. Practically, ‘mach file-info bugzilla-component <test-path>’ can quickly determine the bugzilla component, and nearly all bugzilla components now have triage owners (who are hopefully approved by the module owner and knowledgeable about the module).
Module and triage owners ought to be more familiar with the failing test and the features under test than others, especially people who normally work on other modules. They may have a greater interest in properly fixing a test than someone who has only come to the test because their changeset triggered an intermittent failure.
Also, intermittent failures are often indicative of faulty tests: A “good” test passes when the feature under test is working, and it fails when the feature is broken. An intermittently failing test suggests the test is not reliable, so the test’s module owner should be ultimately responsible for improving the test. (But sometimes the feature under test is unreliable, or is made unreliable by a fault in another feature or module.)
A risk I see with the module owner approach is that it potentially shifts responsibility away from those who are introducing problems: If my patch is good enough to avoid immediate backout, any intermittent test failures I cause in other people’s modules is no longer my concern.
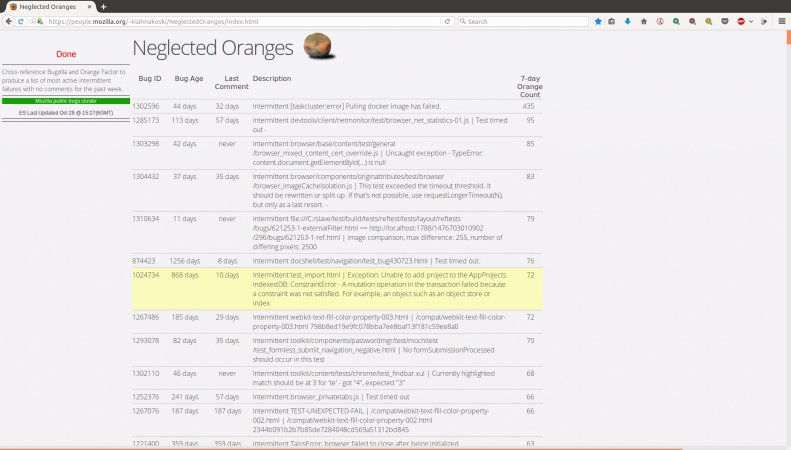
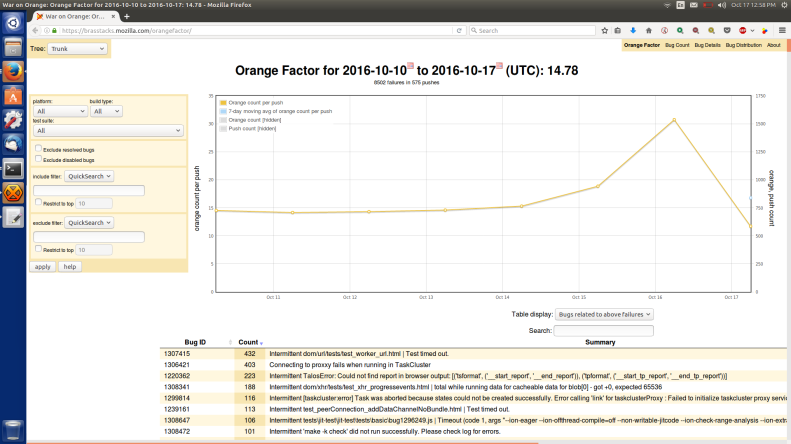
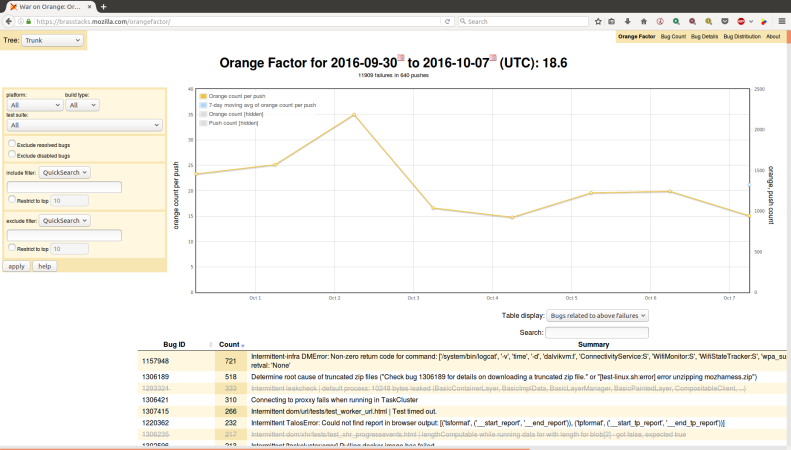
As part of the Stockwell project, :jmaher and I have been using a hybrid approach to find developers to work on frequent intermittent test failure bugs. We regularly triage, using tools like OrangeFactor to identify the most troublesome intermittent failures and then try to find someone to work on those bugs. I often use a procedure like this:
- Does hg history show the test was modified just before it started failing? Ping the author of the patch that updated the test.
- Can I retrigger the test a reasonable number of times to track down the changeset associated with the start of the failures? Ping the changeset author.
- Does hg history indicate significant recent changes to the test by one person? Ask that person if they will look at the test, since they are familiar with it.
- If all else fails, ping the triage owner.
This triage procedure has been a great learning experience for me, and I think it has helped move lots of bugs toward resolution sooner, reducing the number of intermittent failures we all need to deal with, but this doesn’t seem like a sustainable mode of operation. Retriggering to find the regression can be especially time consuming and is sometimes not successful. We sometimes have 50 or more frequent intermittent failure bugs to deal with, we have limited time for triage, and while we are bisecting, the test is failing.
I’d much prefer a simple way of determining an owner for problematic intermittents…but I wonder if that’s realistic. While I am frustrated by the times I’ve tracked down a regressing changeset only to find that the author feels they are not responsible, I have also been delighted to find changeset authors who seem to immediately see the problem with their patch. Test authors sometimes step up with genuine concern for “their” test. And triage owners sometimes know, for instance, that a feature is obsolete and the test should be disabled. So there seems to be some value in all these approaches to finding an owner for intermittent failures…and none of the options are perfect.
When a bug for an intermittent test failure needs attention, who should be contacted? Who is responsible for fixing that bug? Sorry, no clear answer here either! Do you have a better answer? Let me know!